As with many tech nerds, although employed in a specific area of IT I like to dabble in others in my free time. My most recent dabbling has been in data science. Although I say “science” I’m afraid my intentions are less noble than the word implies. I’m more interested in exploiting data for profit.
Odds of that?
Were I a bookmaker setting odds I could simply guestimate the probability of an outcome, knock a bit off for my “fee”, and offer those odds to my pundits. But where’s the profit if no one backs the looser?
The bookies have an awful lot of information at their disposal that they can use to balance a book. For example they know which teams / sports stars are popular with punters and will have a reasonable idea of how many bets they can expect when they offer any given odds. Were I setting odds I would be more interested in predicting how many people will take my odds and for what stakes than the messier business of predicting the outcome of a sporting event.
My goal as a book maker would be to make as much money as possible as reliably as possible. I would not be at all interested in “gambling”. I suspect larger bookmakers already do this, which would put an interesting inefficiency in the market ripe for exploiting in that odds are representative of the punter’s expectation of the outcome and not the probability of the outcome.
Why Tennis?
I like tennis. Well I don’t watch tennis, but if I were to I think I’d like it. Tennis is an ideal candidate sport for odds profiteering for a number of reasons:
- Singles tennis is a simple competition between two players without group dynamics and summing of component parts to account for
- It’s enjoyed by many for the sport itself, meaning a wide range of data is publicly available for fans enjoyment unlike horse racing where useful data is behind a pay-wall
- Underdogs win fairly regularly. In 2016, nearly 28% of matches were won by the underdog[1]
I see predicting which underdogs win as a good area to make money. I theorise there are unsupported, relatively unknown players that few pundits want to back. Bookies will incentivise with higher paying odds on these players to balance their book and remove the gambling element.
I have been exploring this area with machine learning algorithms with promising results.
First Pass
As a proof of concept I used datasets from tennis-data.co.uk and simulated predicting the 2016 season. I used an out-of-band validation technique where for a given day only data from previous days were considered to train the model, and the model was then used to predict that day. In my implementation training the model was the bottleneck, to shorten runtime I tested three days at once meaning the second and third tested days would be using an “outdated” model. I was careful to avoid leakage and deemed this an acceptable compromise as it could only make results worse[2]
I implemented some very simple features based on the data easily available, this was mostly game win percentage per set, and comparisons with competitor and used this to train a predictive model in R to calculate a rough probability of the underdog winning using only data that would have been available before each match.
This probability is combined with the betting odds to calculate a theoretical “average” return[3] for backing the underdog based on my assigned probability.
The Results
My results were very promising indeed. If you back every underdog you loose, some come in but not enough to recoup other lost stakes. But if you were to back every underdog my model estimates to have a theoretical return greater than 1.0 then you would make a profit.
The plot below illustrates the profit made and the number of bets made based on setting the threshold in different places.
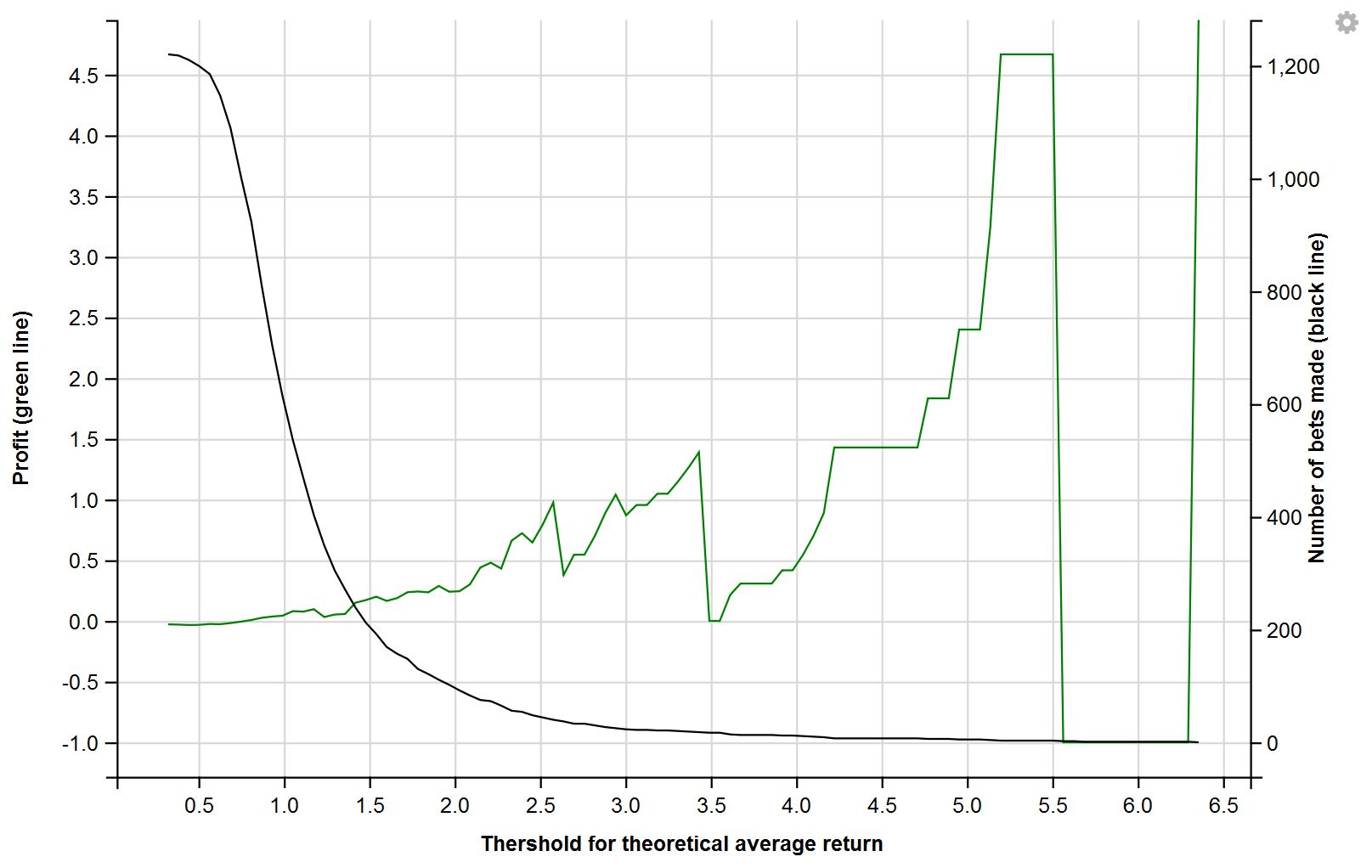
The trick to maximising profit is deciding where to set the threshold for which underdogs you back. This is a conundrum as it is very dangerous to set the threshold for a predictive model with data after the fact.
My biggest criticism of the results is the small number of bets worth making were found. Setting the threshold at 1.5 results in only 200 matches identified as worth betting on across the whole year, and only 36 of these come in. The odds were high enough to recoup losses but these small quantities seem too much like “gambling” and vulnerable to fluctuation. With the limitation of only one reality to test outcomes it is unfortunately impossible to know if this is the good or bad end of possible outcomes.
What next?
I am pleased with the direction of my results but do not believe them conclusive enough to put this into production. I only used a small number of “features” to train my model and believe there to be more valuable mining that can be done here.
The major bottleneck in my experiments was the time it took my computer to train the model in R. The winter holidays has been a good time for me to do this, not only have I had time off work to write my code but also time with family away from my computer allowing it to work whilst I don’t.
To make real progress I need more throughput. I do have experience in c++ but limited access to good machine learning algorithm implementations in it. Learning Spark seems like a good way forward, benchmarks I’ve seen place it way better than R and it’s scale out parallel design would allow me to add more cheap hardware if I see more good results.
Footnotes:
[1] by Bet365’s odds, 734 of 2626 recorded matches (three were excluded for not having odds available).
[2] I’d argue “could” should be read as “should” if this were written by someone else.
[3] Warning, don’t discuss philosophy with a computer guy: A theoretical average where the same match is played a number of times simultaneously in which different results are possible. Assumes “fate” isn’t a thing but also that instances are finite.