This project marks my first dive into deep learning. I have done a lot of data analysis in the past and even dabbled with Neural Networks using TensorFlow but limited these to networks considerably “shallower” than their “deep” cousins.
With previous experiments I have had a relatively small quantity of data compared to the millions of observations production nets are trained on, and I am using a now ageing gaming laptop. Training a deep net from scratch with only 1000 observations will surely result in an over-fit, where no reliable classifications can be inferred on previously unseen validation data.
The aim of this project is to eventually gather millions of brick detections in order to train a model to find bricks from images, eventually taken in real-time on a mobile device. Having recently been introduced to Transfer Learning on Jeremy Howard’s excellent Fast AI Practical Deep Learning for Coders course, I may be able to create something useful with far less manually tagged observations.
Fast AI
Fast AI is a framework designed to make deep learning easier to use. It does require programming and data-manipulation skill but most of the complexities are hidden with default “best practices” to get results which in my opinion are good enough for most users.
I chose to learn from Fast AI largely due to recommendations on the Kaggle forums, and wealth of sample code available including deploying models on AWS’s Lambda service which I intend to use to take the inference load off my web servers.
Transfer Learning
Deep Learning is often used to describe a type of neural networks which have a large number of layers. Typically the initial layers are about detecting gradient changes between neighbouring pixel values. Subsequent layers take those detections and piece them together to detect simple geometry, then from this geometry shapes, then from these objects made from those shapes, in greater detail as the network deepens.
The idea behind transfer learning is we take an existing model trained on many millions of observations, and we add or fine-tune the last layers to detect the specific features which differentiate categories in our own data.
My hope is that by using this technique I can train a network to reliably detect the differences between types of Lego bricks with only thousands of observations.
Prep Work
To date I have labelled 1,303 Lego pieces in my image dataset. For an initial trial I created cropped fragments around the pieces, saving the fragments into sub-folders named after the Lego piece names.

As can be seen above, some distortion has occurred during the crop & resize which I will need to investigate and adjust for. They appear fine in image viewers so I hope this is just a matplotlib quirk.
So far I have many pieces with only a few observations, and a few pieces with many observations. Here I filter my dataset to be the twelve pieces with the most observations. This is not representative of my intended application but sufficient for a simple technology test.
Training
Fast AI’s ImageDataBunch.from_folder() function allows these fragments to be loaded and their labels inferred from sub-folder names, and split into out-of-band test & training data splits in a single (but long) line of code.
Training the model was in not many more lines. As a demonstration of this brevity the whole python code including boiler-plate required to train this model is as follows:
from fastai.vision import *
from fastai.metrics import error_rate
path = Path("img_chips")
np.random.seed(1)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224,
num_workers=4).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(4)Results
My results are not as good as those in the Fast AI lesson. I suspect part of this is how different Lego parts look from top & bottom, but I do have a much smaller dataset (but growing!) than the lesson. More training observations and using rotated copies of current ones should improve results.
Below is a Confusion Matrix, plotting for the out-of-band test data what the parts were identified as vs their true label.
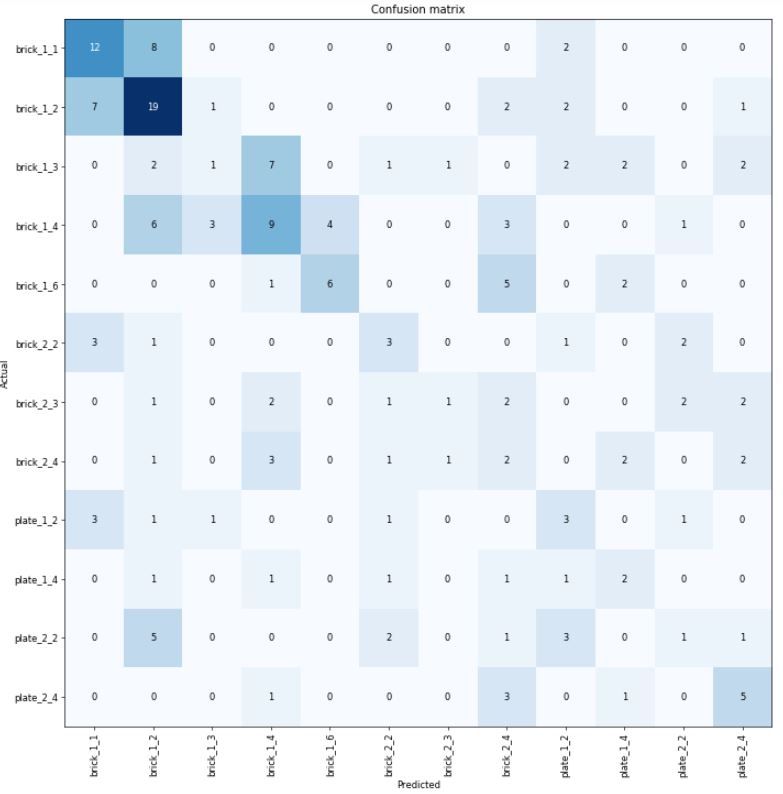
There is a lot of miss-identification here. A fair amount are correctly identified (shown in the diagonal of the matrix) and it is encouraging to see many bricks are at least identified as bricks and plates as plates, albeit different sizes.
Fast AI provides a handy function to view some miss-identified results, so lets look at some:

Of these nine, three of the images do in fact contain the predicted part (top centre, top right, middle centre) even though the centred part was not detected. Arguably my application does not need to achieve 100% accuracy. If a user enters the part they are looking for then the app can simply return locations predicted with the highest probability of being that part. With luck, there will be more than one of them in the pile.
Bye for now
It is still early in this project and my results are not yet at the stage where I can deploy a model but I am extremely impressed with Fast AI and encouraged that this method has legs. I will continue to collect data and acquire knowledge and hope to have a model online in the not too distance future.
The deep learning tests done in this post are from techniques demonstrated in lesson one of Fast AI’s course.

