When I say going serverless, I really mean gone serverless. This is my first new post on my serverless deployment.
This week I passed the AWS Certified Cloud Practitioner exam aiding my employer to climb up a tier on the AWS Partner Program. This site is itself hosted on AWS, although I created is long before needing the certification the hands on experience of deploying even a small solution on AWS was valuable to passing the certification first time. The AWS portfolio of services is broad such that I did have to learn about a lot of services I had not used, inspiring me to re-architect my deployment to better make use of a cloud architecture. I intend to keep learning and take the deeper AWS Certified Solutions Architect Associate exam which further hands-on experience will no doubt be equally valuable.

How clever I thought I was. The past me built a stateless web server to host my website, content stored in an separate services, all hosted in AWS. The web server itself was an EC2 instance with data stored in a separate RDS database instance and media assets on a shared filesystem on EFS. My deployment only had a single instance of each to mostly* keep within the AWS Free Tier but this stateless design would allow me to scale individual resources both horizontally and vertically with little re-configuration.
*The exception being RDS storage. Whilst the RDS instance was free in the free tier, I discovered RDS storage is not. As quite a small site my RDS storage costs were only ~15p a month.
Stateless? 2009 called. They want their infrastructure design principles back. I am going serverless.
No Server?
Of course serverless still runs on servers, it’s just you don’t need to manage them. You just consume a service provided by servers managed by the provider. Two key products in AWS’s portfolio for this are S3 and Lambda.

S3 is a natural fit for hosting web content. Essentially it stores files by a unique URL which can be exposed publicly or routed by domain names etc.. It’s great for static content but lacks any computability for dynamically generated content. It’s worth noting that you can still host “dynamic” sites in S3, it’s just the HTML that has to be static. Other “microservices” can be used or implemented to fill the roles. As demonstration of this you can comment on this very post.
Cost efficiency
With no dedicated apache instance sitting idle, S3 and Lambda deliver amazing economies of scale. I steered clear of these serverless architectures originally as they tend to be proprietary to an individual cloud provider, where as a Linux VM and a SQL-based database can very easily be duplicated on alternative providers. However my original EC2 & RDS based deployment was essentially a “lift and shift”, taking how you would deploy a solution in your own data centre and mimicking it in the cloud.
The timing for going serverless is great. My 12-month AWS Free Tier is not far from running out, I would like to continue hosting my own site and developing my Find My Brick project but I would like it to be cheaper than the resources will soon be costing me.
Sacrifices
There is one feature I have lost from going serverless, and it’s actually the main reason I built the site. Shiny Server. Shiny is a package that allows you to generate interactive web-aps using the R programming language and is what I used to deploy my brick-tagging app. It has both server and client side processes which means it can interact with secure databases server-side whilst offloading render and such to client-side java script libraries.
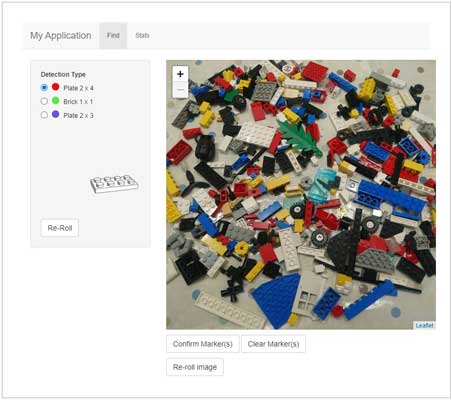
It needs a server, running R & Shiny Server, and in my case also a database. In this new serverless world it had to go. I will keep using R and Shiny, just not in my personal web deployments.
For now, I have moth-balled the brick tagging app. I have all images tagged for my initial dataset, my next move in that project needs to be refine the neural network and deploy an inferencing algorithm, possibly using AWS’s Lambda. If I were to re-deploy the tagging app I would need to re-write it. The functionality can be re-created using Lambda for any pre-calculations such as “randomised” selection, javascript for client-side application, and API calls submitting data to either an S3 bucket or perhaps more manageable as JSONs to a DynamoDB target.
Conclusion
It is nice that you can simply lift & shift your workload to cloud providers and depending on utilisation often realise significant savings, but I am confident serverless is better way for many solutions like web deployments.

